Writing SGEMM Kernels in CUDA

I wanted to get better at writing kernels, so I implemented a few CUDA kernels for SGEMM (Single-precision General Matrix Multiply) on the cheapest NVIDIA hardware I can rent: A10 GPUs.
When it comes to common operations like SGEMM, NVIDIA provides highly optimized
implementations through its proprietary library called cuBLAS (CUDA Basic Linear Algebra
Subroutines). NVIDIA does not ship the CUDA kernel source code itself; rather, it exposes
compiled implementations through a library interface. By calling cublasSgemm,
programmers can use years of NVIDIA’s architecture-specific optimization work rather than
write their own SGEMM kernels from scratch. For this reason, custom kernels are often
evaluated by comparing their performance against cuBLAS.
This writeup is heavily inspired by existing blogs, including this one, this one, and this one (among others). Those posts go much more in depth. My version is going to focus more on what I found interesting and, at a high level, the optimizations I made.
I am going to assume you already know the basics of GPU execution: threads, blocks, warps, global memory, shared memory, registers, and coalescing. If not, I highly recommend reading Programming Massively Parallel Processors.
Problem Setup
I implemented single-precision GEMM:
C = alpha * A * B + beta * Cwhere:
- A is m x k
- B is k x n
- C is m x n
- matrices are stored row-major
- all benchmark cases use square matrices: m = n = k
The benchmark runs every custom kernel against cuBLAS for correctness, then benchmarks repeated launches with CUDA events to get the average GFLOP/s.
The kernels are:
| ID | Kernel | Idea |
|---|---|---|
| 0 | cuBLAS | Reference implementation |
| 1 | Naive | One CUDA thread computes one output element |
| 2 | Shared-memory tiling | Cache tiles of A and B in shared memory to increase arithmetic intensity |
| 3 | Register tiling | Each thread computes a 4x4 output tile using registers |
cuBLAS Reference
The cuBLAS kernel is the baseline. Since cuBLAS assumes column-major storage and my
matrices are row-major, the launcher swaps the order of A and B when calling cublasSgemm
(Note this uses the identity that (AB)T = BT AT.). Swapping
A and B lets the row-major inputs be interpreted correctly through cuBLAS's column-major
interface. This avoids explicitly transposing the matrices before benchmarking.
cublasSgemm(
params.handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
params.n,
params.m,
params.k,
¶ms.alpha,
params.B,
params.n,
params.A,
params.k,
¶ms.beta,
params.C,
params.n);It is interesting to note that cuBLAS assumes column-major storage for backwards compatibility. The original BLAS (Basic Linear Algebra Subroutine) standard was developed in Fortran, which stores matrices in column-major format.
Mentioned above but worth repeating, cuBLAS also serves as the correctness oracle. Before timing each custom kernel, I run cuBLAS on the same input and compare the result elementwise.
Now, let’s get into some kernels.
Kernel 1: Naive Implementation
The naive kernel maps one CUDA thread to one output element of C.
__global__ void sgemm_v1(
int m, int n, int k,
float alpha,
float* A,
float* B,
float beta,
float* C) {
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
float val = 0.0f;
if (x < n && y < m) {
for (int i = 0; i < k; ++i) {
val += A[y * k + i] * B[n * i + x];
}
C[y * n + x] = alpha * val + beta * C[y * n + x];
}
}The launch uses a 32 x 32 block, so each full block computes a 32 x 32 tile of C.
dim3 block_dim(32, 32);
dim3 grid_dim((params.n + 31) / 32, (params.m + 31) / 32);This is the “Hello, World” of SGEMM kernels. Matrix multiplication is embarrassingly parallel, so the most straightforward implementation is to assign each thread the responsibility of computing a single element of output matrix C.
At size 4096, this kernel reaches about 1.45 TFLOP/s, while cuBLAS reaches about 13.41 TFLOP/s on the same run. That is roughly 10.8% of cuBLAS.
Where is the remaining performance going?
The answer lies in the growing gap between computation speed and memory bandwidth.
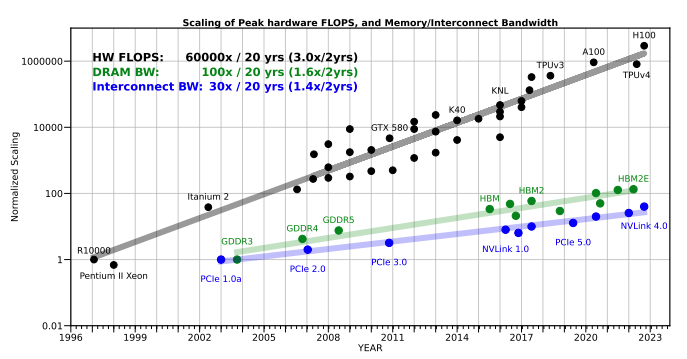
Over the years, compute speed has outpaced memory bandwidth. In practice, this means a GPU core may be able to perform the arithmetic faster than the system can deliver the data it needs. To understand this intuitively, reference the Factorio clip below:
Imagine the blue grabber as the GPU core, the conveyor belt as the I/O path, and the copper as data. Once a piece of copper reaches the grabber, the grabber processes it almost immediately. But then it sits idle, waiting for the conveyor belt to deliver the next piece. That idle time is wasted performance! We want the blue grabber to always be working.
For the naive kernel, performance is bottlenecked by global memory bandwidth. We aren't able to get the data from global memory to the cores fast enough to keep all of the cores occupied. We strive to alleviate this for the second kernel.
Another way to describe the goal is arithmetic intensity: how much useful arithmetic the kernel performs for each value it has to load. The next two kernels try to raise that ratio by reusing data after it has been loaded.
Kernel 2: Shared-Memory Tiling
The second kernel adds the first major optimization: shared-memory tiling.
Instead of having every thread independently stream through global memory, each block cooperatively loads a tile of A and a tile of B into shared memory.
constexpr int BLOCK_SIZE = 32;
__shared__ float Ads[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bds[BLOCK_SIZE][BLOCK_SIZE];Each block still computes a 32 x 32 output tile. But now the dot product is split into phases. In each phase:
- Load a 32 x 32 tile from A into shared memory.
- Load a 32 x 32 tile from B into shared memory.
- Synchronize the block.
- Accumulate partial dot products using shared memory.
- Synchronize again before overwriting the shared tiles.
for (int ph = 0; ph < (k + BLOCK_SIZE - 1) / BLOCK_SIZE; ++ph) {
if (row < m && ph * BLOCK_SIZE + tx < k) {
Ads[ty][tx] = A[row * k + ph * BLOCK_SIZE + tx];
} else {
Ads[ty][tx] = 0.0f;
}
if (ty + ph * BLOCK_SIZE < k && col < n) {
Bds[ty][tx] = B[n * (ty + ph * BLOCK_SIZE) + col];
} else {
Bds[ty][tx] = 0.0f;
}
__syncthreads();
for (int i = 0; i < BLOCK_SIZE; ++i) {
Pvalue += Ads[ty][i] * Bds[i][tx];
}
__syncthreads();
}The key idea is reuse. A loaded value of A can be reused across many columns of C, and a loaded value of B can be reused across many rows of C.
This improves performance, but not dramatically in my implementation. At size 4096, the shared-memory kernel reaches about 2.03 TFLOP/s, or 15.1% of cuBLAS.
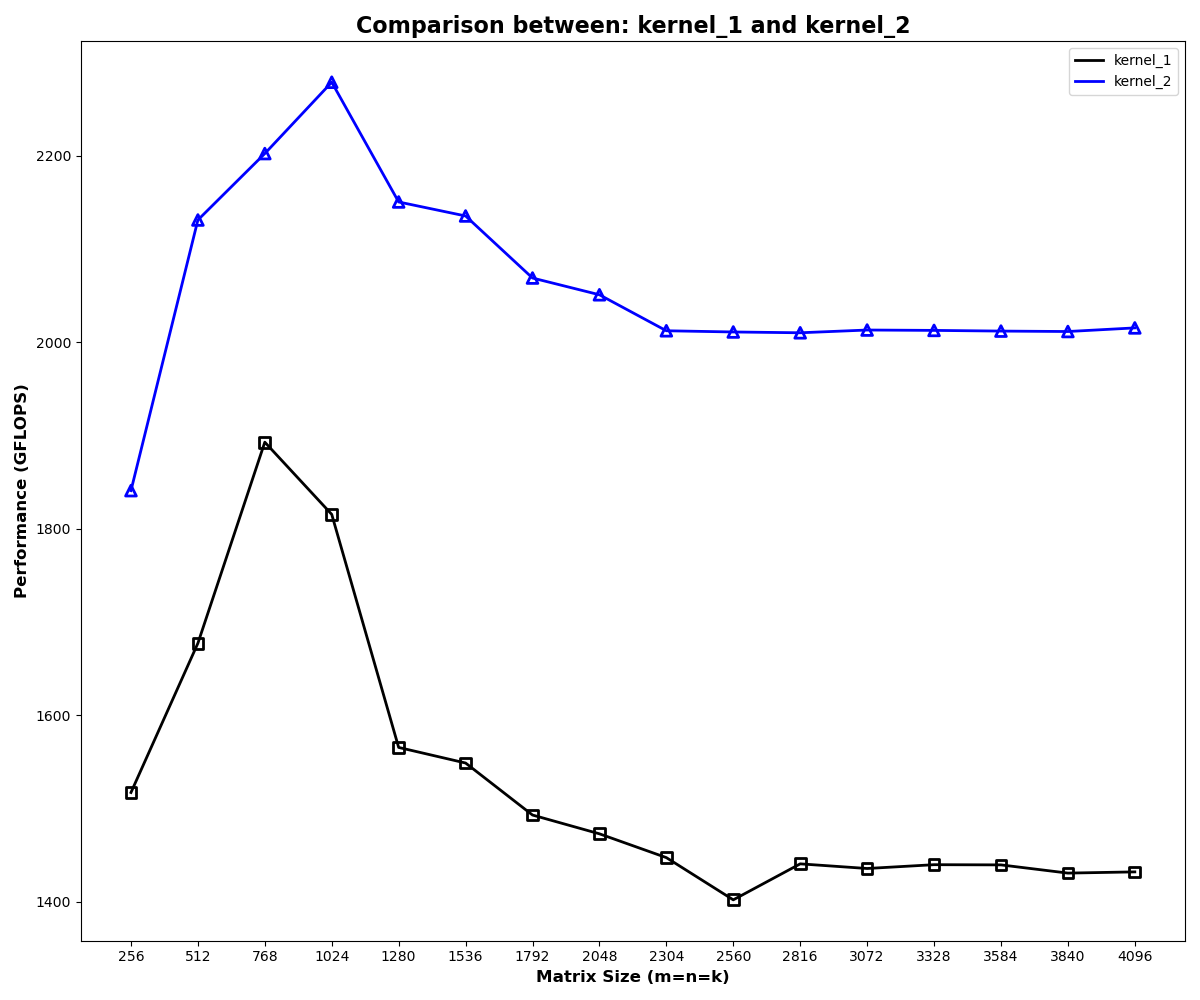
The chart shows the shared-memory kernel consistently above the naive version, but the gap is modest. That is better than the naive kernel, but still far away from cuBLAS.
Kernel 3: Register Tiling
The third kernel changes the amount of work assigned to each thread.
Instead of one thread computing one output element, each thread computes a small 4 x 4 tile of output elements. The block computes a 64 x 64 tile of C, using a 16 x 16 thread block.
constexpr int BLOCK_SIZE = 64;
constexpr int TM = 4;
constexpr int TN = 4;
dim3 block_dim(BLOCK_SIZE / TN, BLOCK_SIZE / TM);So:
block tile: 64 x 64
thread block: 16 x 16 = 256 threads
each thread computes: 4 x 4 = 16 output valuesEach thread keeps its partial sums in registers:
float acc[TM][TN] = {0.0f};The shared-memory tiles are larger now:
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];For each phase, the block cooperatively loads a 64 x 64 tile of A and B. Since there are only 16 x 16 threads, each thread loads multiple shared-memory elements.
// Load shared memory
for (int tr = ty; tr < BLOCK_SIZE; tr += blockDim.y) {
for (int tc = tx; tc < BLOCK_SIZE; tc += blockDim.x) {
int Arow = by * BLOCK_SIZE + tr;
if (Arow < m && ph * BLOCK_SIZE + tc < k) {
As[tr][tc] = A[Arow * k + ph * BLOCK_SIZE + tc];
} else {
As[tr][tc] = 0.0f;
}
int Bcol = bx * BLOCK_SIZE + tc;
if (ph * BLOCK_SIZE + tr < k && Bcol < n) {
Bs[tr][tc] = B[(ph * BLOCK_SIZE + tr) * n + Bcol];
} else {
Bs[tr][tc] = 0.0f;
}
}
}
__syncthreads();Then each thread repeatedly loads a small strip from shared memory into registers:
for (int kk = 0; kk < BLOCK_SIZE; ++kk) {
float regA[TM];
float regB[TN];
for (int i = 0; i < TM; ++i) {
regA[i] = As[ty * TM + i][kk];
}
for (int j = 0; j < TN; ++j) {
regB[j] = Bs[kk][tx * TN + j];
}
for (int i = 0; i < TM; ++i) {
for (int j = 0; j < TN; ++j) {
acc[i][j] += regA[i] * regB[j];
}
}
}By making each thread compute multiple output elements, we increase arithmetic intensity at the thread level. Each loaded value of regA[i] is reused across multiple columns, and each loaded value of regB[j] is reused across multiple rows. The inner loop performs a small outer product and accumulates into sixteen independent registers.
Finally, the thread writes its 4 x 4 tile back to global memory:
for (int i = 0; i < TM; ++i) {
for (int j = 0; j < TN; ++j) {
int row = by * BLOCK_SIZE + ty * TM + i;
int col = bx * BLOCK_SIZE + tx * TN + j;
if (row < m && col < n) {
C[row * n + col] = alpha * acc[i][j] + beta * C[row * n + col];
}
}
}At size 4096, this kernel reaches about 6.27 TFLOP/s, or 46.8% of cuBLAS.
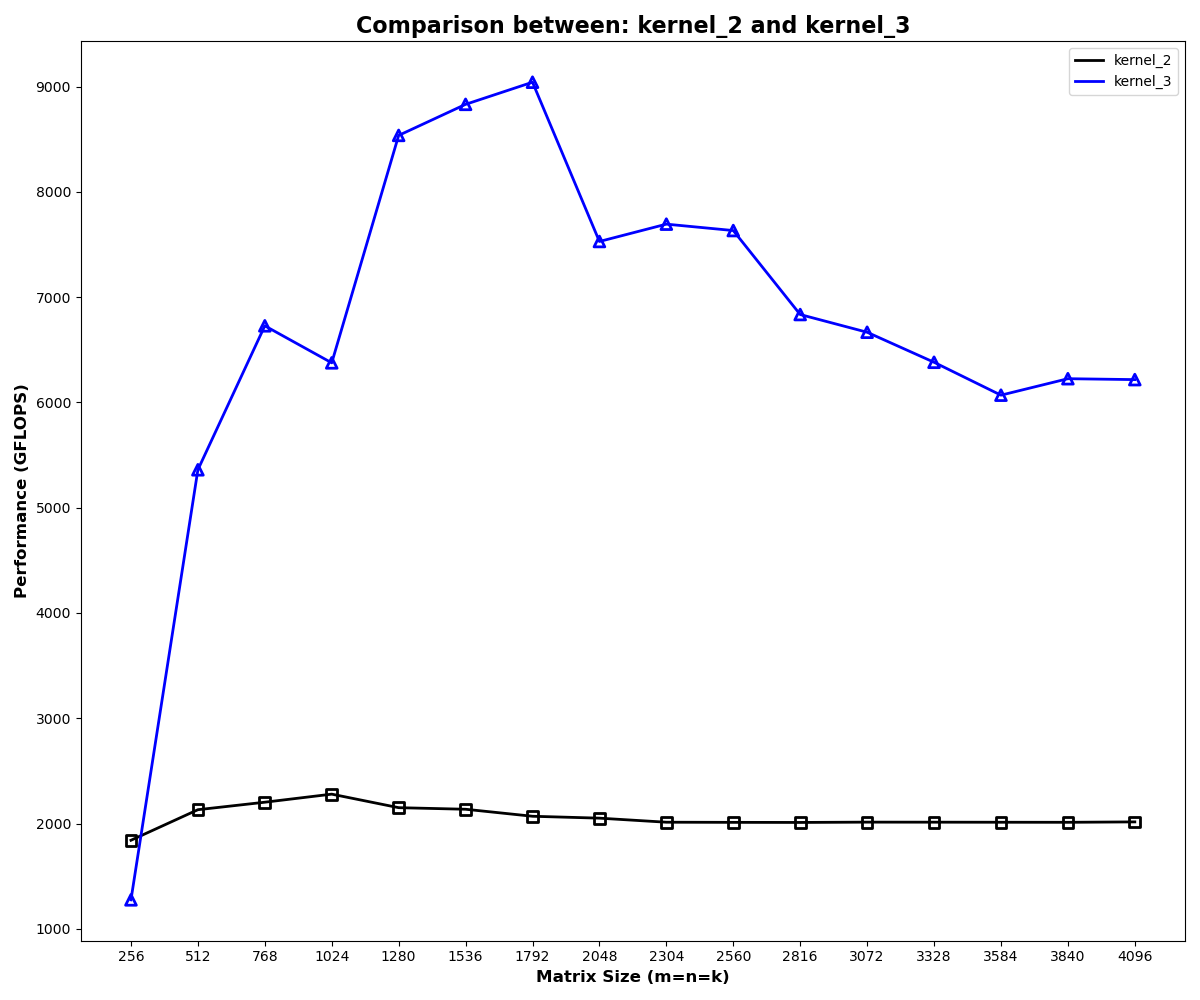
This is the first real jump in the results. Register tiling makes each thread do enough work to reuse loaded values more effectively, so kernel 3 pulls away from the shared-memory-only version across most matrix sizes.
Benchmark Results
Here are selected results from my run on an NVIDIA A10.
| Matrix size (m = n = k) | |||||
|---|---|---|---|---|---|
| Kernel | 512 | 1024 | 1536 | 2048 | 4096 |
| cuBLAS | 10200.2 | 13706.9 | 19450.1 | 18622.7 | 13412.3 |
| Naive | 1676.1 | 1814.8 | 1566.2 | 1505.8 | 1453.8 |
| Shared Memory | 2133.0 | 2280.5 | 2173.4 | 2089.9 | 2026.7 |
| Register Tiled | 5362.9 | 6433.0 | 8956.1 | 7970.2 | 6273.7 |
Relative to cuBLAS:
| Matrix size (m = n = k) | |||||
|---|---|---|---|---|---|
| Kernel | 512 | 1024 | 1536 | 2048 | 4096 |
| Naive | 16.4% | 13.2% | 8.1% | 8.1% | 10.8% |
| Shared Memory | 20.9% | 16.6% | 11.2% | 11.2% | 15.1% |
| Register Tiled | 52.6% | 46.9% | 46.0% | 42.8% | 46.8% |
Shared memory moves the naive kernel in the right direction, but the register-tiled kernel is the clear step change: it stays around 43-53% of cuBLAS across these sizes, while shared memory alone stays around 11-21%.
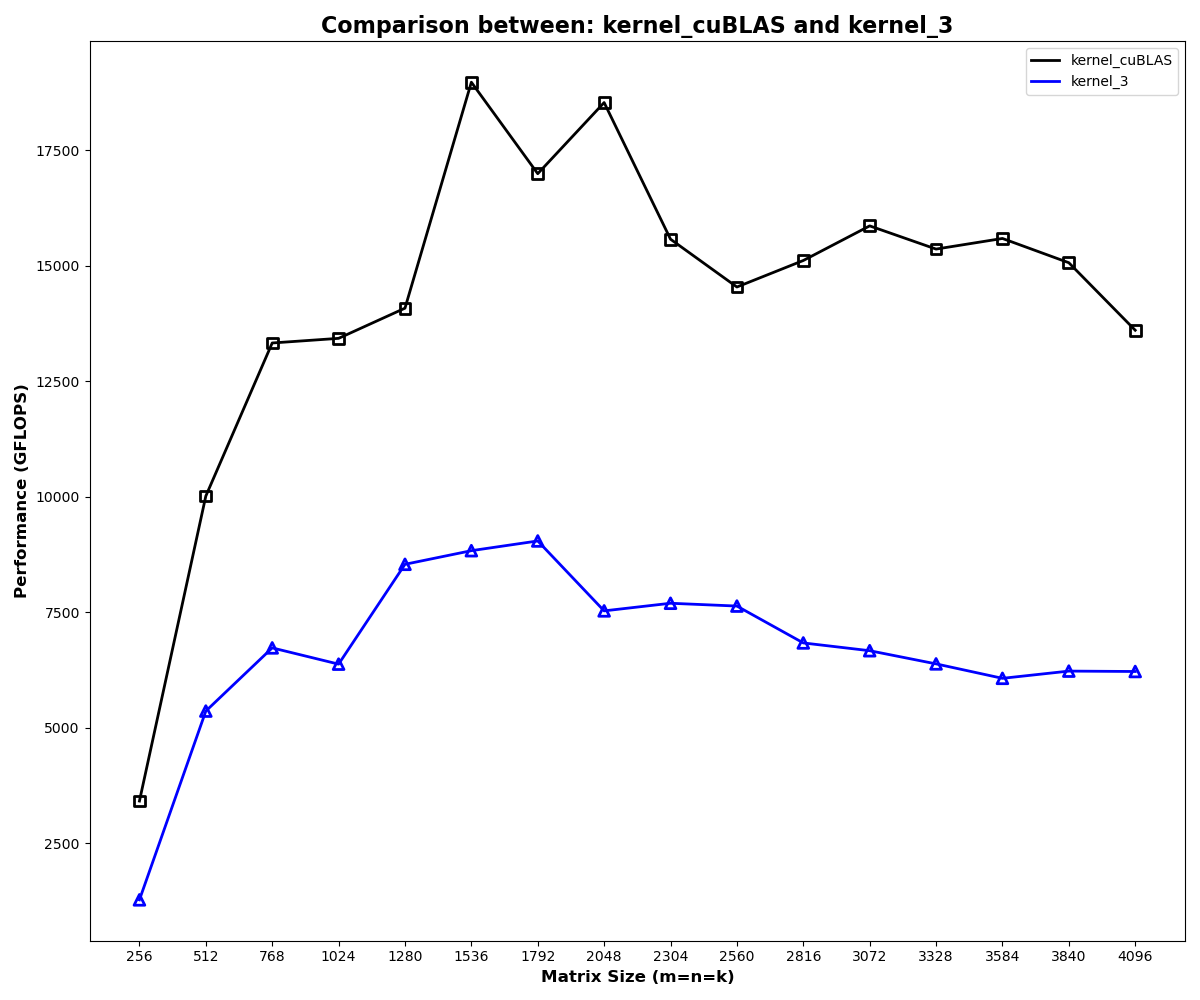
The final comparison keeps the result in perspective. Even after register tiling, cuBLAS is still far ahead, but kernel 3 reaches roughly 43-53% of cuBLAS on the larger benchmark cases.
Summary
I will keep adding kernels to this over time. The main lesson so far is that reducing global-memory traffic helps, but it is not enough by itself. The shared-memory kernel improves reuse at the block level, while the register-tiled kernel improves reuse inside each thread. To check out the code and benchmarking pipeline, the code can be found here.